VLA papers at AAAI-2026
A few weeks ago, I visited Singapore to attend the AAAI conference and present our SPARC paper that was accepted as an oral! (See more at the bottom of this page.) As someone who’s starting in the field of Vision-Language-Action models, it gave me a nice opportunity to discover relevant papers in the area. In this brief blog I’ll share some of the interesting VLA papers that I’ve come across. Let me know if there are more that I missed!

Most of these papers were presented in the Embodied AI 2 oral session on Jan 23, 2026. To me this was by far the most interesting session of the conference!
DiTEA
This work uses Mixture of Experts to improve multi-task learning in VLAs. They prevent weight conflict by separating tasks into different experts. Provides stronger multi-task learning capability.

VLA-Adapter
Tiny scale VLAs. They provide a clever way to bridge “VL” to “A”, enabling the use of smaller VLM backbones (0.5B params, vs 7B in OpenVLA). This gives faster inference, but still maintains ~97% performance on the LIBERO benchmark. Quite popular on GitHub already (2k stars).

DexGraspVLA
Using VLAs for dexterous grasping (with a human-like robotic hand, instead of the more standard parallel jaw gripper). They test on thousands of unseen cluttered scenes. Building on DINOv2 as the visual encoder, and using a diffusion transformer (DiT) to generate action chunks. Also includes masking with SAM to highlight the current object of interest. Website: dexgraspvla.github.io.

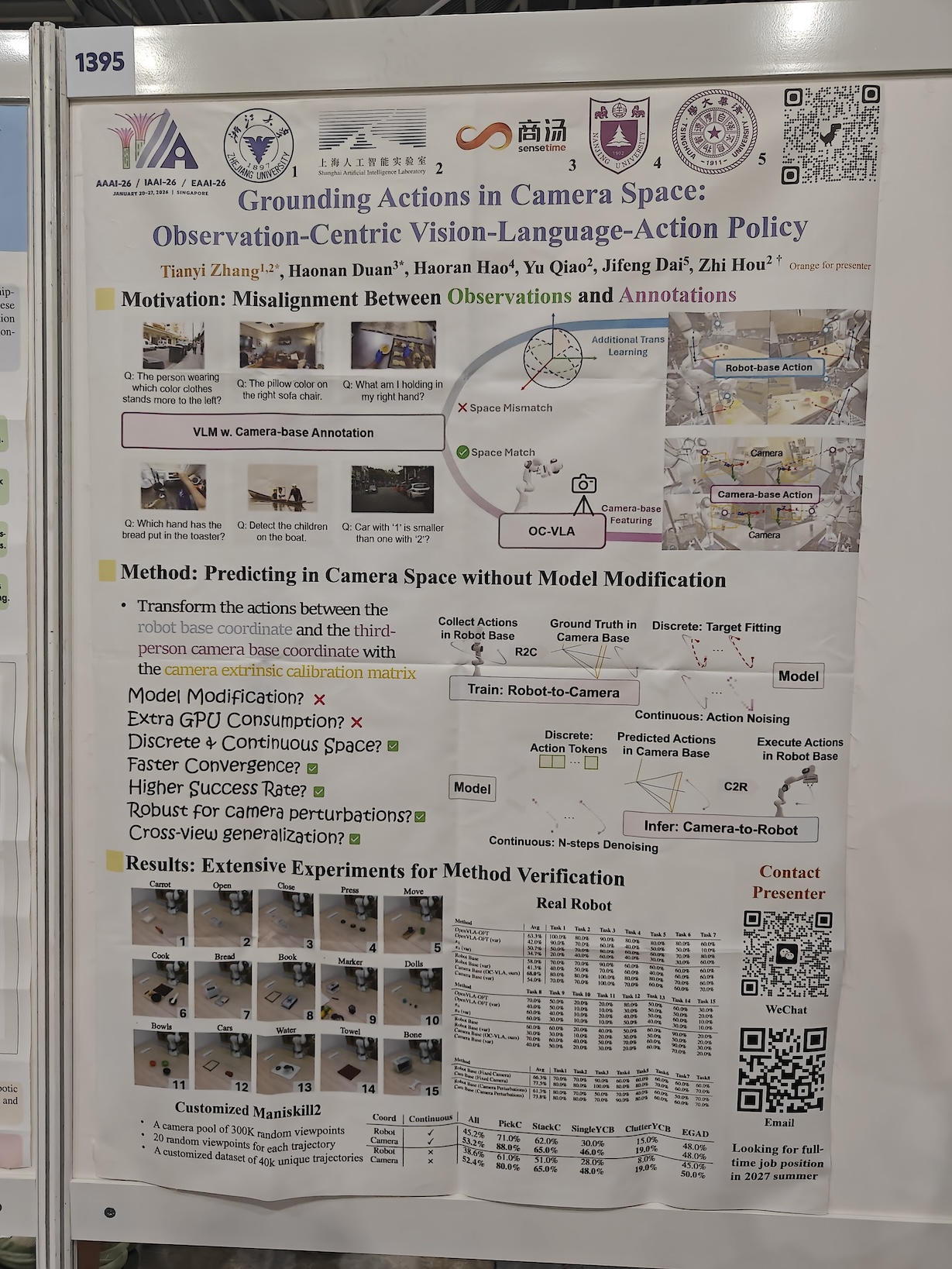
Grounding Actions in Camera Space
This is a nice & simple idea to improve the performance of your VLA: transform the 7-dim action space coordinates of the robot’s end-effector ⟨x,y,z,roll,pitch,yaw,gripper⟩ from the robot base coordinate system to the third-person camera coordinate system. This transformation grounds the VLA’s actions in its actual observations (from the camera). Just this simple adjustment can improve performance by 10-20%. Paper: arxiv.org/abs/2508.13103.
CCoL
Continuous Co-Learning in VLAs. A method that avoids physical discontinuities using neural ordinary differential equations (NeuralODEs). Furthermore, it strengthens semantic-physical alignment through a bidirectional cross-attention mechanism. Website: qhemu.github.io/CCoL.
TCoT
Trajectory Chain-of-Thought for robotic manipulation with failure recovery in VLAs. I chatted with Xiang Li at her poster. Similar to ECoT (Embodied Chain-of-Thought), the TCoT method uses the principles of “chain-of-thought” reasoning that work well in LLMs, and applies them to VLAs. The difference is that ECoT reasons in object bounding boxes and end-effector positions, while TCoT seems to plan an entire global (course) and local (fine-grained) trajectory for the end-effector. Code: github.com/Serenos/TCoT.
FoAM
Foresight-Augmented Multi-task imitation policy for robotic manipulation. The method predicts visual outcomes of actions to enhance decision-making. Furthermore, it can deal with multi-modal goal inputs, such as image and language prompts (instead of just a language prompt). Website: projfoam.github.io.
Keynote by Peter Stone
I’d like to highlight two interesting keynotes at AAAI. Peter Stone talked about methods that figure out by themselves what to learn, instead of just how to learn. Specifically, I found these projects fascinating:
- SLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL. A clever way to bridge the sim2real gap by exploring more effectively in a latent action space. Website: robo-rl.github.io.
- RLZero: Direct Policy Inference from Language Without In-Domain Supervision. Generating a video of imagined behavior from a language prompt, to then easily follow this with a pretrained unsupervised RL policy. Paper: arxiv.org/abs/2412.05718.
Keynote by Katerina Fragkiadaki
Katerina presented many interesting projects, centered around “Embodied Agents that See, Simulate, and Reason.” She talked about 3Difying the current VLAs, for example with the UniVLG approach.1Sidenote: I recently read Vincent Sitzmann’s blog on the bitter lesson for computer vision, where he argues that we actually won’t need 3D inputs.
Furthermore, Katerina shared useful knowledge on VLAs, e.g., that diffusion seems to work better than regression for action generation. The speculated reason being the ability of diffusion models to better model the multi-modal distributions of actions, instead of simply regressing to the (suboptimal) average. However, she did mention that a recent paper “Much Ado About Noising” seems to find other, more prominent reasons.
Finally, she mentioned the RoboArena, that we should all be using more for our VLA evaluations. And when talking about simulation, she predicted that “in 5 years we won’t have physics engines anymore, it’s all going to be neural.”
More VLA background
See the nice overview blog State of VLA Research at ICLR 2026 by Moritz Reuss. He mentions important simulation benchmarks, their current SoTA scores, and many relevant papers of course.
How to present your research
In the rest of this blog, I’d like to share a few miscellaneous tips and comments. Many presentations at academic conferences are almost impossible to follow, so here are some easy tips on how this can be improved:
- Keep the content simple. Don’t present to impress, present to share ideas.
- Look at your audience, not at your laptop. Of course, you can look at your slides sometimes, but this should only be as a reminder for yourself. Practice your presentation, so you can look at your audience >90% of the time.
- Be at your poster during your entire poster timeslot! At AAAI, it often happened that I found an interesting poster on VLAs, but nobody was there to present it. People won’t read your poster, they want to hear you explain it! Unfortunately, I estimate that about 50% of the posters were missing a presenter:

Just some other comments
- This was the first time AAAI was held in Asia! I love when global conferences are held outside the seemingly default North American location. There were so many Chinese-speaking researchers attending in Singapore, that at some posters the default language was Chinese, and I felt bad asking them to switch to English. I should probably learn some Chinese!
- In the conference app of AAAI, I was searching for “VLA” to see which posters to visit. This worked well for the most part, except that it sometimes brought me to unrelated posters by authors named Vladimir ;)
- When I hear at least two independent people mentioning the same paper, it suddenly gets a much higher spot on my reading list. I tried to summarize this in a meme:

SPARC paper
Our paper on Single-Phase Adaptation for Robust Control (SPARC) was accepted as an oral, which was the main reason of my attendance at AAAI 2026. See the presentation here:
Presentation of the SPARC paper at AAAI, Jan 2026.
It is based on the work I did during my internship at Sony AI. We aimed to create a single RL agent that can drive all the ~500 cars in the PlayStation game Gran Turismo 7. This required some clever techniques to improve generalization, like providing the environment’s context and history to the agent. Read more in the paper on arXiv. I hope to build on this RL and generalization experience in my research on VLAs.